
sklearn基于信息熵的决策树算法实践
以餐馆的经营数据为样本,天气,周末,促销,销量。首先将天气分类为好和坏(经验),销量分类为高和低(均值)。然后将因子规整。采用信息熵的决策树模型进行训练。结果导出为dot文件。
采用graphviz,可以查看结果
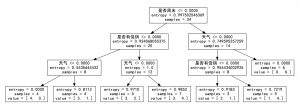
另:graphviz的dot在mac os 10.11.6下有bug,会提示一个lib未能加载。
以下为代码:
#-- coding:utf-8 --
In [2]:
import pandas as pd |
In [3]:
filename = '/Users/frontc/book/ppdam/sales_data.xls' # 样本数据文件路径 |
In [4]:
data = pd.read_excel(filename,index_col=u'序号') # 读取数据到dataframe中 |
In [5]:
data[:4] # 查看一下样本数据 |
Out[5]:
| 天气 | 是否周末 | 是否有促销 | 销量 | |
|---|---|---|---|---|
| 序号 | ||||
| 1 | 坏 | 是 | 是 | 高 |
| 2 | 坏 | 是 | 是 | 高 |
| 3 | 坏 | 是 | 是 | 高 |
| 4 | 坏 | 否 | 是 | 高 |
In [6]:
# 数据规整 |
In [7]:
x = data.iloc[:,:3].as_matrix().astype(int) # 自变量:天气,是否周末,是否有促销 |
In [8]:
y = data.iloc[:,3].as_matrix().astype(int) # 因变量:销量 |
In [9]:
from sklearn.tree import DecisionTreeClassifier as DTC # 导入决策树类 |
In [10]:
dtc = DTC(criterion='entropy') # 初始化决策树模型,采用信息熵模式 |
In [11]:
dtc.fit(x,y) # 训练模型 |
Out[11]:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None, |
In [12]:
from sklearn.tree import export_graphviz |
In [16]:
with open("tree.dot","w") as f: |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 LeFer!
评论