读取SQL Server 事务日志 发表于 2019-03-25 | 更新于 2021-11-02
| 字数总计: 921 | 阅读时长: 3分钟 | 阅读量:
开始 使用下面的脚本开始
CREATE DATABASE [Crack_Me]; GO USE Crack_Me; GO CREATE TABLE [dbo].[Crack_Me_If_You_Can]( [ID] [int] PRIMARY KEY IDENTITY NOT NULL, [Insert_Date] [datetime] NOT NULL, [Some_Data] [varchar](100) NOT NULL, [Optional_Data] [varchar](50)NULL, [Life_the_Universe_and_Everything] [int] NOT NULL, ); GO INSERT INTO [Crack_Me_If_You_Can] ( Insert_Date, Some_Data, Optional_Data, Life_the_Universe_and_Everything ) VALUES (GetDate(), 'Don''t Panic', 'Share and Enjoy', 42); GO SELECT * FROM Crack_Me_If_You_Can; GO
到此为止,我们得到了一些数据去测试。我们将使用一个未被官方文档收录的函数去查看事物日志。
SELECT * FROM fn_dblog(NULL, NULL)
然而,粗略一看,你就会发现返回的日志远远多于你刚才执行的insert操作。为了缩小范围,仅仅去关注我们感兴趣的,我们需要找出AllocUnitId 。 AllocUnitId可以被认为是Crack_Me_If_You_Can表的一个身份实例。我说实例 ,是因为AllocUnitId 在发生重大的模式变化时会改变。
下面的查询语句将列出数据库中所有被用户创建的对象。
SELECT allocunits.allocation_unit_id, objects.name, objects.id FROM sys.allocation_units allocunits INNER JOIN sys.partitions partitions ON (allocunits.type IN (1, 3) AND partitions.hobt_id = allocunits.container_id) OR (allocunits.type = 2 and partitions.partition_id = allocunits.container_id) INNER JOIN sysobjects objects ON partitions.object_id = objects.id AND objects.type IN ('U', 'u') WHERE partitions.index_id IN (0, 1)
这样我们得到了Crack_Me_If_You_Can的allocation_unit_id。这样我们可以改进我们的事物日志查询语句。
SELECT * FROM fn_dblog(NULL, NULL) WHERE AllocUnitId = 72057594039828480
现在我们收缩了返回的数据范围,仅仅五行。我们可以通过限制操作为”LOP_INSERT_ROWS “,进一步去除无效数据。
SELECT * FROM fn_dblog(NULL, NULL) WHERE AllocUnitId = 72057594039828480 AND Operation = 'LOP_INSERT_ROWS'
下面的语句是上面语句的集合。
DBCC TRACEON(2537) SELECT [Current LSN], Operation, dblog.[Transaction ID], AllocUnitId, AllocUnitName, [Page ID], [Slot ID], [Num Elements], dblog1.[Begin Time], dblog1.[Transaction Name], [RowLog Contents 0], [Log Record] FROM ::fn_dblog(NULL, NULL) dblog INNER JOIN ( SELECT allocunits.allocation_unit_id, objects.name, objects.id FROM sys.allocation_units allocunits INNER JOIN sys.partitions partitions ON (allocunits.type IN (1, 3) AND partitions.hobt_id = allocunits.container_id) OR (allocunits.type = 2 and partitions.partition_id = allocunits.container_id) INNER JOIN sysobjects objects ON partitions.object_id = objects.id AND objects.type IN ('U', 'u') WHERE partitions.index_id IN (0, 1) ) allocunits ON dblog.AllocUnitID = allocunits.allocation_unit_id INNER JOIN ( SELECT [Begin Time],[Transaction Name],[Transaction ID] FROM fn_dblog(NULL, NULL) x WHERE Operation = 'LOP_BEGIN_XACT' ) dblog1 ON dblog1.[Transaction ID] = dblog.[Transaction ID] WHERE [Page ID] IS NOT NULL AND [Slot ID] >= 0 AND dblog.[Transaction ID] != '0000:00000000' AND Context in ('LCX_HEAP', 'LCX_CLUSTERED') DBCC TRACEOFF(2537)
探索页 看一看[Page ID]和[Slot ID]的值,我的是’0001:00000016’ 和 0。使用你的值替换下面语句,并执行这个查询脚本。
DECLARE @pageID$ NVARCHAR(23), @pageID NVARCHAR(50), @sqlCmd NVARCHAR(4000); SET @pageID$ = '0001:00000016' SELECT @pageID = CONVERT(VARCHAR(4), CONVERT(INT, CONVERT(VARBINARY, SUBSTRING(@pageID$, 0, 5), 2))) + ',' + CONVERT(VARCHAR(8), CONVERT(INT, CONVERT(VARBINARY, SUBSTRING(@pageID$, 6, 8), 2))) SET @sqlCmd = 'DBCC PAGE (''Crack_Me'',' + @pageID + ',3) WITH TABLERESULTS' EXECUTE(@sqlCmd)
向下滚动,你能看到Slot ID的值。在Field和Value列,你可以看到之前插入的列名和值。看到这里你可能会问,为什么我们不直接采用这种方式获取数据呢?
两个原因:首先,对于一个集群表的数据不总是在同样的PAGE ID 和 SLOT ID,为了优化和重组空间发生变化。在一个数据库中,什么时候发生重组是不可预期的。不过,如果你的表是是一个HEAP,那么这个方法看起来很好,因为HEAP的PAGE ID 和 SLOT ID 是一直保持不变的。其次是因为为了得到每一条记录我们需要频繁调用DBCC PAGE,对SQLSERVER 是一种负担。
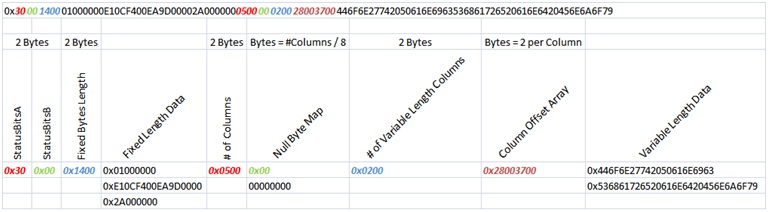
记录结构 回到主题:通过fn_dblog 查询的RowLog Contents 0抓取数据。他的内容是:
0x3000140001000000779FFE0082A700002A000000050000020028003700446F6E27742050616E6963536861726520616E6420456E6A6F79
想理解这条记录是如何组织的需要看一下下面的表格。
彩色的条目是标准的,对于一个INSERT操作,由固定和可变长度的列构成。